
NIO
Netty的底层是NIO(non-blocking io:非阻塞IO)。
NIO的三大组件:
- Channel:数据的传输通道
- Buffer:缓存读写数据
- Selector:选择器
Channel
常见的Channel有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
buffer
常见的buffer有:
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
Selector
多线程版服务器通信连接
普通的服务器网络通信采用的是多线程处理,即每个客户端的请求都会创建一个线程来进行通信连接,
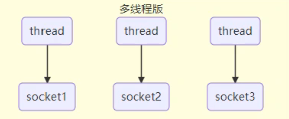
多线程版缺点:
- 内存占用高:线程本身就占用内存(如windows下一个线程1M),随着线程的增加内存就不够,出现内存溢出。
- 线程上下文切换成本高:同一时刻CPU只能处理CPU所能处理的线程数,其余线程处于等待状态,等待时还会将当前的执行状态加以保存,轮到该线程时再将这些数据加以恢复,是比较耗时的。
多线程版只适合连接数少的场景。
线程池版服务器通信连接
为了限制线程数据,通常会想到线程池的方法,避免内存占用和上下文切换问题:
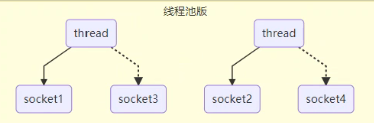
线程池版缺点:
阻塞模式下,线程只能处理一个socket连接,即使该socket没有做任何事,该线程也会一直等着该socket,直到该socket断开后才会处理下一个socket,线程的利用率不高。
线程池版只适用于短连接场景,如:http请求。
selector版服务器通信连接
selector的作用就是配合一个线程来管理多个channel,获取这些channel上发生的事件,当channel发生需要线程处理的事件后,selector就会通知线程来处理该事件,同时channel工作再非阻塞模式下,不会让线程吊死在一个channel上。
selector版适合连接特别多,但是流量低的场景。
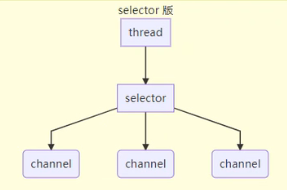
调用selector的select()会阻塞直到channel发生了读写就绪事件,select()方法就会返回这些事件交给线程来处理。
buffer和channer的简单使用
public static void main(String[] args) {
// FileChannel 数据的读写通道
try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {
// 准备缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10); // 划分10个字节作为缓冲区
while (true) {
// 从 channel 读取数据,向 buffer 写入数据
int len = channel.read(buffer);
log.debug("读取到的字节数:{}", len);
if (len == -1) { // 没有内容了
break;
}
// 打印 buffer 的内容
buffer.flip(); // 切换到读模式
while (buffer.hasRemaining()) { // 是否还有剩余未读数据
byte b = buffer.get(); // 每次读一个字节
log.debug("读取到的字节:{}", (char) b); // 因为测试内容都是字符,直接强转打印
}
// 读完一次后,切换为写模式
buffer.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
}
channel作为文件的读写通道,然后暂存到buffer中。
ByteBuffer使用方式

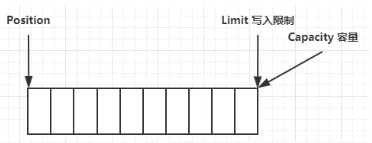
ByteBuffer数据结构
ByteBuffer重要属性:
- capacity:容量
- position:指针
- limit:限制
刚创建时:
写模式下,position是当前写入位置,limit等于容量:
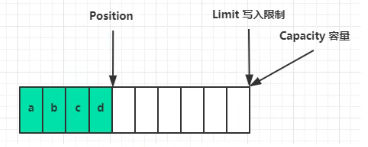
flip()(读模式)动作发生后,position切换为读取的开头位置,limit切换到最后写位置,即能读的最大限制:
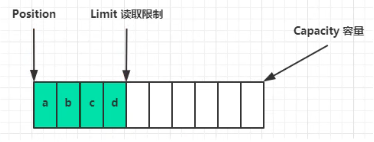
读取到limit后即结束:
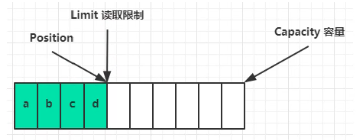
clear()动作发生后,回到创建时的状态:
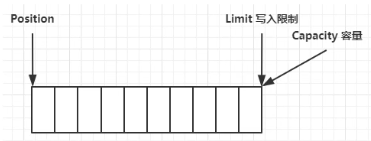
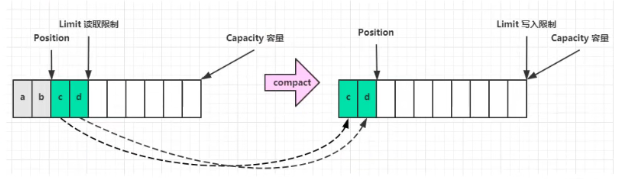
另外一种切换写模式方法,compact()方法是把未读完的部分向前压缩,然后切换到写模式:
ByteBuffer常见方法
内存分配
allocate()分配的是Java堆内存,效率受GC的影响,allocateDirect()分配的是直接内存,读写效率高(少一次数据的拷贝)。
此处的原因是,如果到Java内存不够时会触发垃圾回收机制,会将分配的Java内存进行一次搬迁,触发数据的拷贝,而直接内存不会触发这个数据的拷贝,效率更高。
但是直接内存也有缺点,直接内存在内存分配时调取的是操作系统的函数,所以分配内存的效率比较低。同时直接内存使用完后如果清理不干净将造成内存泄漏。
注意两种分配内存的方法在创建后都无法动态调整大小,Netty对ByteBuffer做了增加,实现了动态调整内存大小。
写入数据
- 调用channel的
read()方法 - 调用buffer自己的
put()方法
读取数据
- 调用channel的
write()方法 - 调用buffer自己的
get()方法
get()方法会让读指针向后移,如果想重复读取数据,可使用以下方法:
- 调用
rewind()方法将指针重置为0 - 调用
get(int i)方法获取索引i的内容,它不会移动读指针 mark()可以标记指针的位置,reset()是将指针的位置重置到mark()位置,是对rewind()的增强,自由调整读取位置
ByteBuffer与字符串的转换
// 字符串转ByteBuffer
ByteBuffer buffer1 = ByteBuffer.allocate(10);
buffer1.put("hello".getBytes());
// 以上方式转字符需要切换到读模式
// 指定编码
ByteBuffer buffer2 = StandardCharsets.UTF_8.encode("hello");
// wrap
ByteBuffer buffer3 = ByteBuffer.wrap("hello".getBytes());
// ByteBuffer转字符串
String str1 = StandardCharsets.UTF_8.decode(buffer1).toString();
分散读取
// 分散读取,适用于已知读取内容又需要分解内容的情况
try (FileChannel channel = new RandomAccessFile("data.txt", "r").getChannel()) {
ByteBuffer buffer1 = ByteBuffer.allocate(3);
ByteBuffer buffer2 = ByteBuffer.allocate(3);
ByteBuffer buffer3 = ByteBuffer.allocate(5);
channel.read(new ByteBuffer[]{buffer1, buffer2, buffer3});
// 读取
buffer1.flip();
buffer2.flip();
buffer3.flip();
// ...
} catch (IOException e) {
e.printStackTrace();
}
集中写入
// 集中写入,减少数据的拷贝
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("hello");
ByteBuffer buffer2 = StandardCharsets.UTF_8.encode("world");
ByteBuffer buffer3 = StandardCharsets.UTF_8.encode("buffer");
try (FileChannel channel = new RandomAccessFile("data.txt", "rw").getChannel()) {
channel.write(new ByteBuffer[]{, buffer1, buffer2, buffer3});
} catch (IOException e) {
e.printStackTrace();
}
