
锁的作用
从根本上讲,锁的作用是保证数据的一致性,只要能保证分布式并发下抢占同一资源是有序性(排队),那么就能保证数据的一致性,这样来想,锁的实现可以是数据库、缓存等方式,利用排他性让各个请求顺序进行
这里需要理解:分布式锁必然是一个介于服务应用之外的参照组件,与单机架构相比,使用网络通信肯定会降低性能。同时分布式的核心作用是分治,将请求压力分散到各个服务器上,提高并发性能,而不是单次请求性能,所以分布式对于单个请求来说性能是低下的
单体架构中的锁
在单体架构中,不考虑性能的话,解决并发问题使用synchronized就能解决功能性问题
但需要注意的是:synchronized只在同一个JVM中有效,如果是分布式的架构,多个环境(多个JVM)运行,synchronized就不起作用了
还需要JVM锁吗
其实在不同的场景下,考虑维度是不一样的,而且并不是有了分布式就提高了服务的性能,这跟机器多少联系不大,有个误区是服务器多了就能忽略IO和吞吐等性能问题
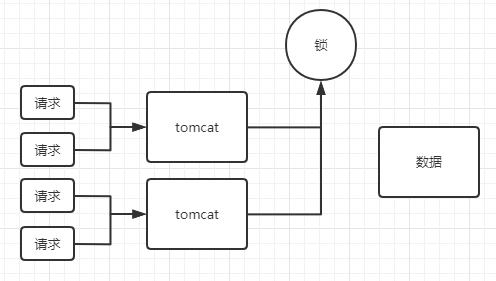
考虑性能的话有了分布式锁其实还是要考虑JVM锁的,并发过来的请求同一时刻最终也只有一个能抢到锁,如果JVM没有锁,所有请求都会压到锁服务上,加上JVM锁后,就减少了对获取锁的请求,Tomcat获取锁后JVM分配给各个用户请求,较少IO,提高性能
分布式锁应该具备的条件
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
- 高可用的获取锁与释放锁
- 高性能的获取锁与释放锁
- 具备可重入特性
- 具备锁失效机制,防止死锁
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
CAP理论
任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项
所以,很多系统在设计之初就要对这三者做出取舍,在互联网领域的绝大多数的场景中,容错性都必须要保证,所以会选择牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终一致性是在用户可以接受的范围内即可
基于Redis实现分布式锁
因为Redis的数据在内存中,读写性能高,所以大部分分布式锁方案都是基于Redis实现,其核心是Redis的setnx命令

在SpringBoot中的核心代码
Boolean setFlagResult = redisTemplate.opsForValue().setIfAbsent("flag", "test", 5, TimeUnit.SECONDS);
Redission
Redission是一种基于Redis实现的分布式锁,可以用于分布式系统中协调并发访问同一资源
// 第一步:引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.14.0</version>
</dependency>
// 第二步:创建Redisson客户端,连接到Redis服务
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
// 第三步:使用,“myLock”是锁的名称
RLock lock = redisson.getLock("myLock");
lock.lock(); //加锁
try {
//执行业务逻辑
} finally {
lock.unlock(); //释放锁
}
// 其他操作
//判断锁是否被当前线程持有
if (lock.isHeldByCurrentThread()) {
//执行业务逻辑
}
//获取锁的状态信息
LockState lockState = lock.getState();
